 Syno?C 引物合成
Syno?C 引物合成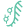 RNA合成
RNA合成 mRNA合成
mRNA合成 Syno?GS 基因合成
Syno?GS 基因合成 載體構建
載體構建 高通量及DNA文庫構建
高通量及DNA文庫構建 CRISPR基因編輯平臺
CRISPR基因編輯平臺 病毒包裝
病毒包裝 基因測序及分析
基因測序及分析 重組蛋白表達平臺
重組蛋白表達平臺 抗體工程平臺
抗體工程平臺 多肽服務
多肽服務 生物信息學分析與設計
生物信息學分析與設計 CRISPR文庫
CRISPR文庫 ProXpress蛋白快速檢測
ProXpress蛋白快速檢測 CRISPR 質粒
CRISPR 質粒
在生物技術的前沿領域,AI 正在掀起一場蛋白質研究的革命。AI 幫助科學家以前所未有的精度預測蛋白質結構和功能、從頭設計新型蛋白質、解開生命分子層面的奧秘。蛋白質生產技術的進步,如AlphaFold 和人工智能驅動技術,不僅改寫了蛋白質研究的規則,也為從藥物開發到疾病診斷和合成生物學等各個領域帶來了許多可能性。
人工智能在蛋白質結構預測中的作用
蛋白質研究一直是生物技術領域中的核心難題,其復雜性源于蛋白質多樣的三維結構和動態特性。長期以來,科學家們一直使用X射線晶體學、核磁共振(NMR)和冷凍電子顯微鏡等傳統工具來解析蛋白質結構。然而,這些方法往往成本高昂、耗時,并對特定蛋白質類型的解析存在局限性。這些傳統技術在應對蛋白質的動態性和環境依賴性方面也有較大挑戰,導致實際解析的結構可能無法準確反映蛋白質在生理條件下的狀態。科學家們亟需新的工具,能夠更快速、高效、低成本地完成復雜蛋白質結構的預測與解析,以滿足現代生命科學研究的需求。
AI如何突破蛋白質研究困境?
隨著計算機技術和算法的不斷進步,科學家們開始探索使用人工智能和機器學習方法來解決蛋白質結構預測問題。
2020年,DeepMind 團隊推出了突破性工具 AlphaFold,并經歷了不斷的發展和完善。該模型利用深度學習精確預測蛋白質三維結構,顯著提升了蛋白質結構預測的準確性和速度,為生物學研究帶來了革命性進展。AlphaFold 使用深度學習模型,通過分析多序列比對 (MSA) 中的進化協變數據,預測氨基酸殘基之間的距離,從而揭示蛋白質結構的空間構造。。神經網絡會預測一個 “距離圖 ”或殘基-殘基距離的概率圖,為折疊過程提供指導。利用這些距離信息,該模型會進行優化(如梯度下降),以確定蛋白質的最終三維結構。
2020年,AlphaFold 2.0 在蛋白質結構預測競賽 CASP14 上一鳴驚人,獲得了98.5%的蛋白質結構預測率。作為 Alphafold 的升級版本,它能在幾分鐘內預測出典型蛋白質的結構,精度通常在 1 ? 以內,接近碳原子寬度(約 1.4 ?)。這種精確度代表了計算生物學的重大飛躍,為了解蛋白質折疊的復雜性提供了強有力的工具。
AlphaFold 2.0 引入了一種名為 Evoformer 的先進神經網絡架構。該架構利用進化和空間關系處理多序列比對(MSA)和成對殘基信息。通過三角更新和注意力機制,幫助模型捕捉遠程依賴性和空間關系,這對準確預測蛋白質折疊至關重要。它還包括一個結構模塊,直接預測三維原子坐標,并采用循環機制進行迭代優化。通過端到端訓練和獨特的自蒸餾過程,AlphaFold 2達到了接近實驗的精度,能夠預測以前具有挑戰性的復雜和新型結構。
AlphaFold 2.0 模型架構
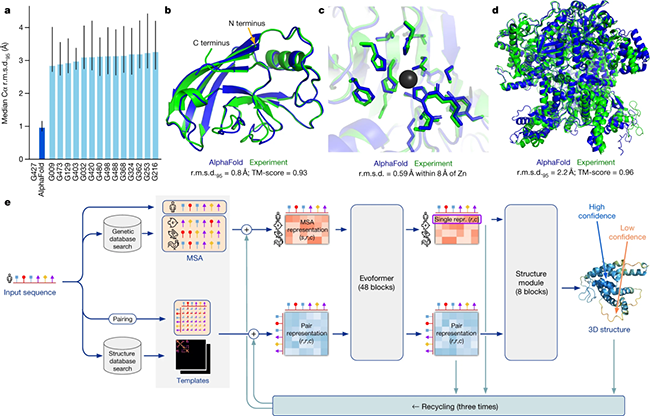
2021年, David Baker的團隊推出了革命性工具 RoseTTAFold。這一開源蛋白質結構預測工具采用了獨特的三軌網絡架構,能夠同時處理序列、距離和坐標信息,使得預測的精準度和速度顯著提高。
? 序列軌道:處理氨基酸序列信息。
? 距離軌道:處理氨基酸對之間相互作用的信息。
? 坐標軌道:處理局部結構特征,如二級結構和溶劑可及性。
RoseTTAFold 的三維軌道架構
該模型在不同通道中同時處理序列、距離和坐標信息,通過通道間的信息不斷交換來迭代完善蛋白質結構。RoseTTAFold 的設計實現了一種多任務學習方法,可以同時優化多個相關任務,如距離圖預測、角度圖預測和接觸圖預測,有助于提高整體預測精度。
人工智能在蛋白質功能預測中的作用
蛋白質的功能是在基因本體(GO)中被定義的,其依據分子功能(MFO)、在生物過程里的作用(BPO)以及在細胞成分中的位置(CCO)來對蛋白質實施分類。借助對同源蛋白質的注釋,諸如UniProtKB/Swiss - Prot這類數據庫,為數千種生物以及超過55萬種蛋白質提供了經過整理的GO數據。
然而,數據庫中大部分蛋白質缺少功能注釋,現有的注釋大多源于耗時的實驗。基于AI的預測方法,融合了氨基酸序列、結構信息以及蛋白質 - 蛋白質相互作用(PPI)網絡,使得蛋白質功能預測更加高效,顯著提高了預測準確性和速度。這為填補蛋白質功能注釋的空白提供了可擴展的解決方案。。通過運用深度學習和文獻知識,這些工具能夠更高效且更精準地進行功能預測,從而加深我們對蛋白質在健康和疾病中所起作用的理解。
DeepGO 是第一個基于深度學習的預測模型,它通過將深度學習應用于蛋白質序列和相互作用數據來預測蛋白質功能。該模型以蛋白質的氨基酸序列作為輸入,使用卷積神經網絡(CNNs)從中提取特征。DeepGO 還結合了蛋白質-蛋白質相互作用(PPI)網絡,使模型能夠利用蛋白質之間的功能關系。通過這種方法,DeepGO 分配基因本體(GO)術語,根據分子功能、生物過程和細胞成分對蛋白質功能進行分類,這對全面的蛋白質功能預測很有效果。
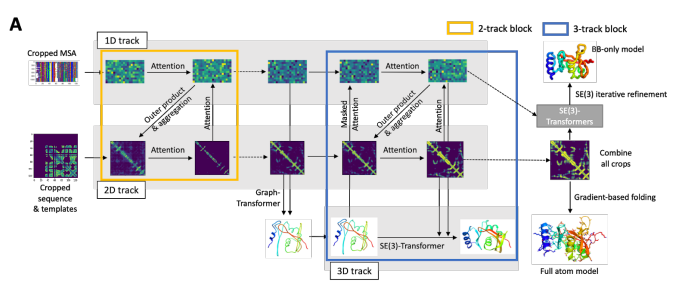
DeepGO-SE 是一種用于蛋白質功能預測的高級模型,它通過一種稱為近似語義蘊含的過程,將基因本體(GO) 中的知識納入其中。該模型的運行分為三個關鍵步驟:
1. 構建近似模型:利用GO的公理和蛋白質功能斷言創建近似模型,其中ELEmbeddings以幾何表示法捕捉GO 中的語義關系。
2. 蛋白質嵌入和優化:蛋白質序列用預訓練的ESM2模型的嵌入表示。然后在近似模型中對這些嵌入進行定位,以最大限度地提高“蛋白質具有C功能 ”這樣的語句的可能性,從而指導精確的功能預測。
3. 多模型聚合:重復這個過程以生成多個模型,最終預測基于所有模型中都成立的真值,有效地捕捉蘊含關系。
DeepGO-SE模型
人工智能在蛋白質設計中的應用
蛋白質設計已經有了顯著的發展,從最初通過PCR的誘變引入特定突變來調控蛋白質結構,到應用先進計算方法構建具有所需特性的新型蛋白質。如今,隨著結構生物學、計算建模的快速發展,AI蛋白質設計比以往任何時候都更加精確,也更容易獲得。AI驅動的設計技術既能優化蛋白質,增強蛋白質的天然功能(如親和力和穩定性),還具備從頭構建全新蛋白質的能力,以實現特定的功能、結構和應用,為藥物發現、工業酶工程等領域帶來前所未有的創新可能性。
ProteinMPNN 是一種用于高效蛋白質序列設計的深度學習模型,它繞過了傳統基于物理的方法(如Rosetta)的計算需求。通過直接從結構數據中學習并編碼空間關系, ProteinMPNN 能準確預測折疊成目標結構的序列。該模型在設計復雜的組裝(如四面體納米粒子)和保持結合親和力(即使發生點突變)方面表現出色。該模型能夠創建各種類型的蛋白質,包括單體、組裝體和納米顆粒,是提高蛋白質溶解度、穩定性和功能性的強大工具。
RFdiffusion 采用創新方法,利用擴散模型,通過迭代去噪,將蛋白質骨架從最初的噪音細化為現實結構。通過結合特定的結構基序,它創造出多樣化、復雜的蛋白質,以滿足特定需求,如對稱組裝體和功能基序。RFdiffusion在生成新型拓撲結構方面的精確性使其能夠應用于前沿領域,從治療支架到復雜結構設計。
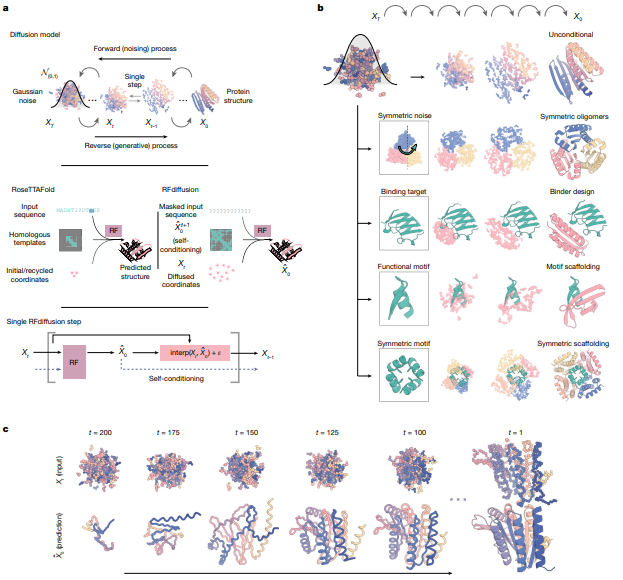
利用RFdiffusion設計蛋白質
ProGen 借鑒NLP的語言模型技術,生成反映進化模式和生化特性的蛋白質序列,從而能夠創建具有特定功能的序列。ProGen使用轉換器來模擬驅動穩定性和功能性的序列特征,使其高度適用于各種應用,從酶設計到生成具有特定結合親和力的序列。
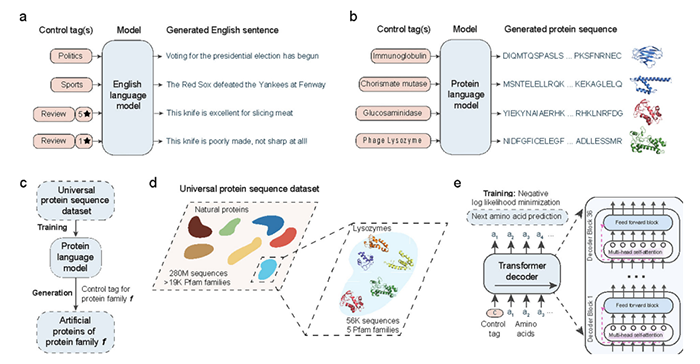
利用條件語言建模生成人工蛋白質
AlphaProteo 專注于創建高親和力蛋白質結合劑,利用結構引導序列生成技術開發針對精確蛋白質位點的結合劑。通過將生成模型與高級過濾器相結合。AlphaProteo在生產針對具有挑戰性的目標(如病毒和癌癥相關蛋白質)的結合劑方面表現出色,在許多情況下實現了亞納摩爾親和力。它能夠簡化粘合劑設計,減少優化次數,為治療開發開辟了新的可能性。
AlphaProteo 在測試的七種目標蛋白質上都有較高的實驗成功率。在濕實驗室測試中,9% 到 88% 的候選分子成功結合,比其他方法高 5 到 100 倍;比現有最佳方法的結合親和力高 3 到 300 倍。
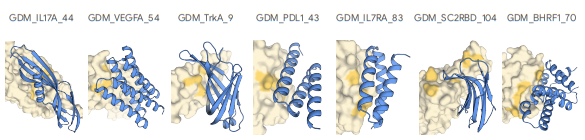
從AI蛋白設計到濕實驗驗證
研究人員現在能夠直接從序列和結構數據中生成針對特定功能(如結合親和力、穩定性和催化活性)優化的蛋白質。然而,將這些計算設計轉化為功能性、可靠的蛋白質需要嚴格的濕實驗驗證,以確保結合親和力、穩定性和生物活性等特性。在濕實驗驗證過程中,科學家面臨許多挑戰,復雜蛋白質的結構和性質可能導致其在表達過程中出現折疊異常或形成無活性的聚集體,極大地降低表達效率。濕實驗的數據反饋至關重要,可用于進一步優化AI模型,從而提高模型對未來設計的精準度和有效性。
泓迅生物為研究人員提供了一站式解決方案,簡化了從數字序列到經過實驗驗證的蛋白質產品的過程。與我們合作,您只需提供蛋白質序列,我們會處理從密碼子優化和基因合成到表達系統選擇、蛋白質純化和功能驗證的每一個細節。
- 密碼子優化:我們的NG Codon技術提高表達,針對您的特定表達系統進行了優化。
- 基因合成與克隆:高保真基因合成并克隆到任何指定的載體中。
- 表達系統篩選:可使用細菌、酵母、昆蟲和哺乳動物宿主進行定制表達。
- 重組抗體表達:通過整合抗體基因序列、從頭抗體設計、抗體人化、抗體基因合成、重組抗體表達、單克隆抗體制備和多克隆抗體制備,涵蓋抗體發現的所有階段。
- 大規模蛋白質生產:靈活的生產規格,從微克到克,以支持任何規模的項目。
- 質量與功能驗證:全面的測試確保最終蛋白質或抗體產品的可靠性、活性和功能性。
全球AI蛋白質公司
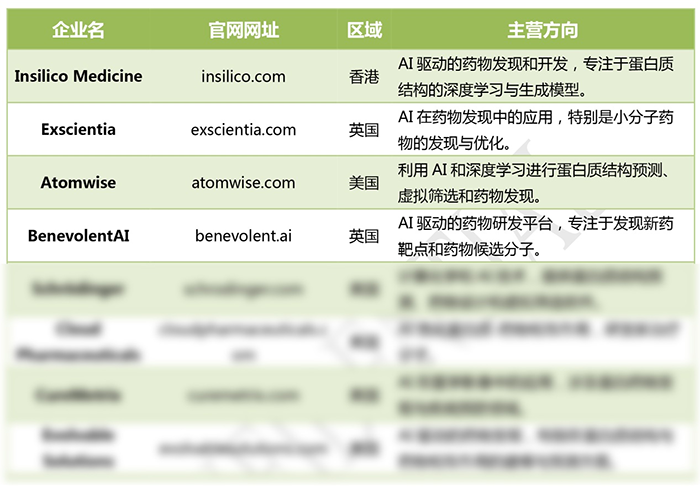
部分公司,聯系我們申請完整版本
AI在蛋白質科學中的應用多樣性已經在重塑藥物發現、精準醫學和合成生物學。由David Baker等先驅孵化的公司正在使用深度學習來解決關鍵的生物學挑戰,包括藥物開發、多肽設計、小分子結合蛋白質工程和新型材料合成。隨著AI加速和增強蛋白質設計的能力得到證明,其在生物技術中的作用預計將不斷增長,為定制療法和創新生物材料開辟新的可能性,并推動生命科學領域的邊界不斷拓展。
References
[1] Jumper, John, et al. "Highly accurate protein structure prediction with AlphaFold." nature 596.7873 (2021): 583-589.
[2] Baek, Minkyung, et al. "Accurate prediction of protein structures and interactions using a three-track neural network." Science 373.6557 (2021): 871-876.
[3] Madani, Ali, et al. "Large language models generate functional protein sequences across diverse families." Nature Biotechnology 41.8 (2023): 1099-1106.
[4] Senior, Andrew W., et al. "Improved protein structure prediction using potentials from deep learning." Nature 577.7792 (2020): 706-710.
[5] Zambaldi, Vinicius, et al. "De novo design of high-affinity protein binders with AlphaProteo." arXiv preprint arXiv:2409.08022 (2024).
[6] Kulmanov, Maxat, et al. "Protein function prediction as approximate semantic entailment." Nature Machine Intelligence 6.2 (2024): 220-228.
[7] Watson, Joseph L., et al. "De novo design of protein structure and function with RFdiffusion." Nature 620.7976 (2023): 1089-1100.


























